
前幾天介紹了 可觀察性 (Observability),來幫助我們了解應用程序的狀態與快速反應問題,今天我們將借助可觀察性中的 Metrics 並搭配 Kubernetes 的 水平自動伸縮 (Horizontal Pod Autoscaler) 功能,來提升系統的強韌度。
水平自動伸縮 (Horizontal Pod Autoscaler),簡稱 HPA,是一個用於自動調整應用程序的 pod 副本數的控制器。HPA 的主要目標是根據應用程序的流量和資源(例 cpu, memory) 使用情況,自動增加 或 減少 pod 的數量,以確保應用程序在不同負載下保持穩定運行。
真實環境下系統收到的請求量都會依據尖峰與離峰時段而增減,若依據尖峰時段的流量來配置固定的 Pod 數量,當離峰時段時,Pod 能承受的流量會遠遠大於實際流量,造成不必要的資源浪費與成本。相反的依離峰時段配置固定 Pod 數量,則可能在尖峰時段出現服務不可用的狀況。
而 HPA 能依據流量或資源使用狀況來調整 Pod 的副本量,在尖峰時段使用較多的 Pod 處理流量,而離峰時段減少 Pod 來節省成本。
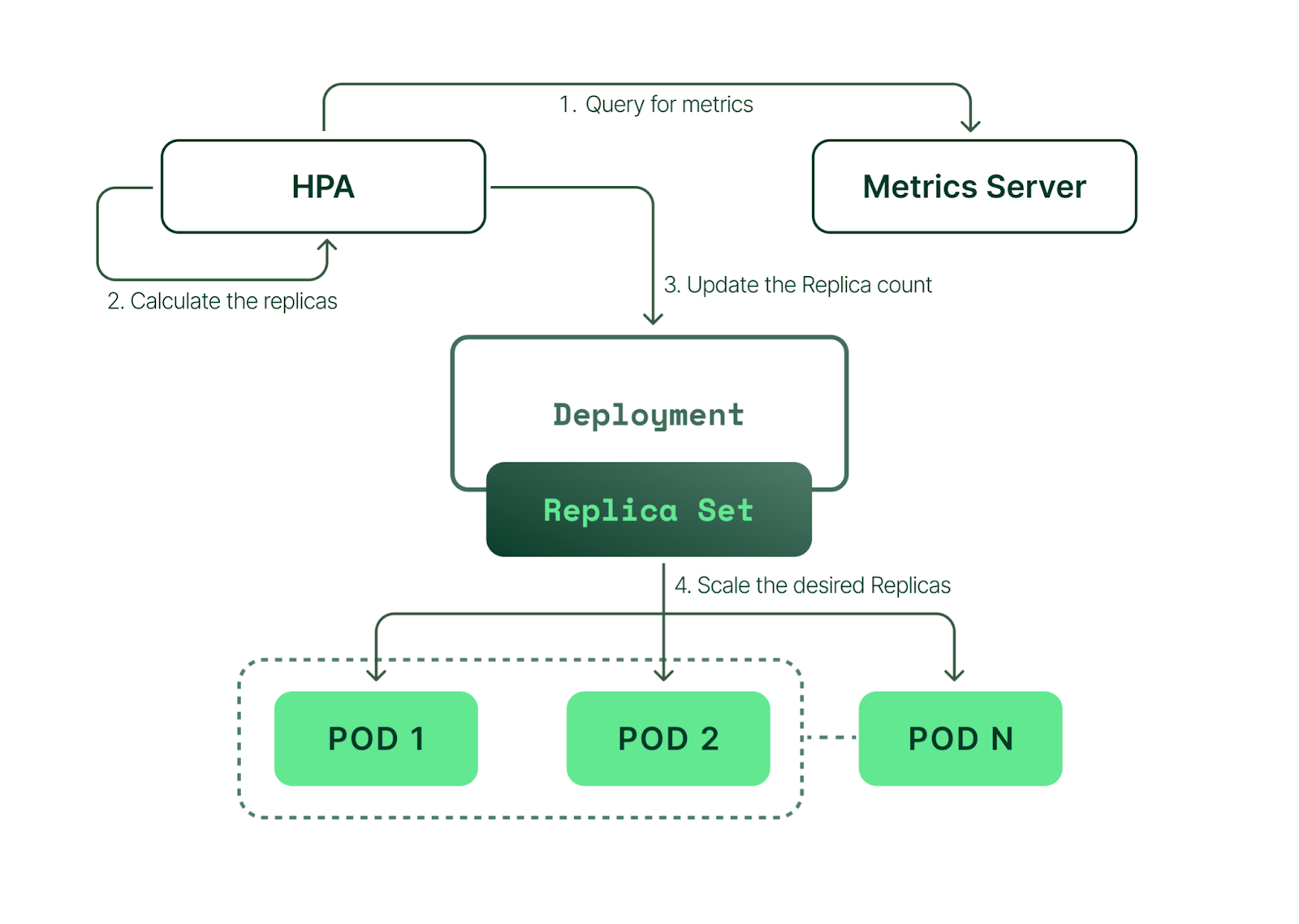
圖檔來自 - kubecost/Kubernetes HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
namespace: my-namespace
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
scaleTargetRef: 指定要自動縮放的目標資源,通常是一個 Deployment 或 ReplicaSet 的引用。它包括 apiVersion、kind 和 name。
minReplicas: 指定 HPA 允許的最小副本數。即使指標超出閾值,也不會縮減副本數至低於此值。
maxReplicas: 指定 HPA 允許的最大副本數。當指標超出閾值時,HPA 可以擴展副本數,但不會超過此值。
metrics: 定義 HPA 使用的指標來自動縮放的方式。通常,您會指定 CPU 和/或內存使用率的指標以及相關的閾值。
type: 指定指標的類型,可以是 Resource(資源使用率)或 Object(自定義指標)。resource: 如果 type 為 Resource,則指定資源的名稱(如 cpu 或 memory)和使用率閾值(如 averageUtilization 或 averageValue)。Kubernetes cluster 需安裝 Metrics-server,安裝方式能參考 Metrics-server 文檔
運行一個 Deployment
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
EOF
部署 HPA
cat <<EOF | kubectl apply -f -
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 3
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
EOF
這個 HPA 觀察 Deployment/php-apache 的 cpu 使用率的 metrics,當 cpu 使用率超過 50% 時,自動進行水平擴展,新增更多 Pod 出來,最多成長到 3 個 Pod,當 cpu 使用率低於 50% 時,減少 Pod 數量,最少不低於 1 個 Pod。
檢視 Pod 與 HPA
$ kubeclt get pod
NAME READY STATUS RESTARTS AGE
php-apache-5b56f9df94-69j7t 1/1 Running 0 2m59s
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 3 1 22s
能看到目前只運行一個 php-apache 的 Pod,且 HPA TARGETS 欄位顯示了 CPU 使用率為 0%,擴展閥值為 50%
啟動一個 load-generator Pod 對 php-apache Pod 持續進行流量請求,提高 php-apache Pod 的 CPU 負載
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
等待數十秒後,再重新檢視 pod 與 hpa 的狀態
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
php-apache-5b56f9df94-69j7t 1/1 Running 0 27m
php-apache-5b56f9df94-7r5gc 1/1 Running 0 112s
php-apache-5b56f9df94-d2msz 1/1 Running 0 2m7s
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 159%/50% 1 3 3 22m
能 hpa 觀察到 cpu 使用率提升超過 50%,且 Pod 依照 hpa 的定義,也成長到 3 個 Pod 來接收流量。
load-generator Pod 的流量請求,按下 Control + C,讓 cpu 使用量下降$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pod/php-apache-5b56f9df94-d2msz 1/1 Running 0 12m
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 3 1 37m
簡單來看,擴展與縮減的計算方式能參考以下公式
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
舉例:
1 個 Pod,且 metrics currentMetricValue 為 200m,而 desiredMetricValue 為 100m1 * (200.0/100.0) = 2,故將擴展 Pod 為 2 個2 個 Pod,且 metrics currentMetricValue 為 50m,而 desiredMetricValue 為 100m2 * (50.0/100.0) = 1,故將縮減 Pod 為 1 個因 metrics 通常不是穩定的,會有數據增減的波動,若數據剛好在 HPA 的閥值上波動,可能會導致頻繁增減 Pod 數量,為了避免觸發這種不必要的擴展或縮容,Kubernetes 中提供 horizontal-pod-autoscaler-tolerance 參數能配置,該參數預設為 0.1,代表容忍 0.1 的誤差值,具體來說 (currentMetricValue / desiredMetricValue) 計算出 0.9 ~ 1.1 之間的值,則此次不進行擴展或縮減
通常對擴展的要求都是越快越好,為了快速承接外部增加的流量,所以擴展 Pod 是沒有冷卻時間的。但為了保持系統穩定,會希望不要因為短時間內的數據波動頻繁的增減 Pod,所以 HPA 在縮減 Pod 時,預設會依據前五分鐘的 metrics 歷史紀錄,取最大值來計算 Pod 數量,具體來說,要前五分鐘 metrics 計算出的預期 Pod 數量都小於當前 Pod 數量,才會觸發縮減,這能有效地減少短時間的數據波動,導致 Pod 數量頻繁浮動的現象。
今天簡單了介紹 HPA 的運作原理 跟 使用方式,希望對讀者再提高系統高可用性與節省成本的面向上有所幫助。

 iThome鐵人賽
iThome鐵人賽